この記事はでぶ Advent Calendar 2022 10日目の記事です。
こんにちは、クルトンです!
この記事ではデブさんのツイートを用いて、ツイート内容といいね数の相関について調べた結果を書いていこうと思います。
この記事を書くに至ったきっかけ
殆どの方はご存じかと思いますが、念のために書いておくとデブさんは😡界隈の第一人者として有名なツイッタラーです。
そのツイートの多くには大量の😡が含まれています。

そこで僕は「😡系インフルエンサーのデブさんなら😡を多くすればするほどいいね数が増えるのではないか?」という仮説を立てました。
そのため、この記事ではデブさんのツイートを分析し、😡がいいね数に与える影響について調べようと思います。
TwitterAPIでツイートを取得する
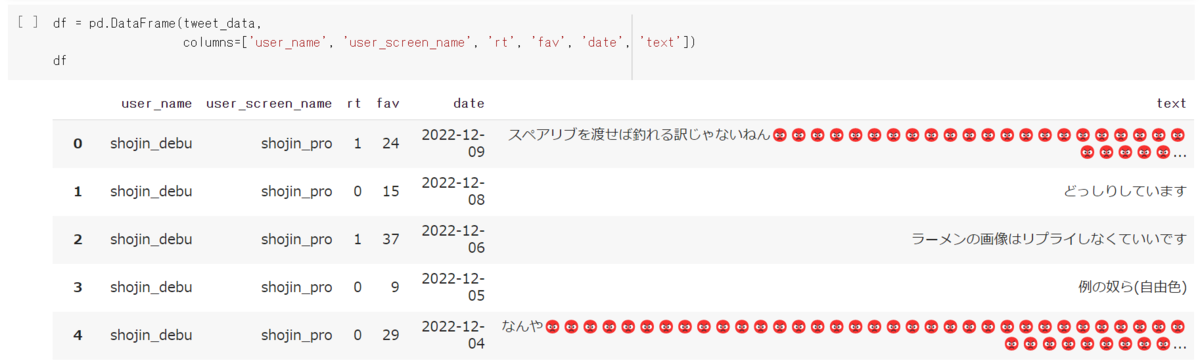
まずTwitter API v2を用いてデブさんのツイートを取得します。
Twitter API v2にはEssential, Elevated, Academic Researchの3つのアクセスレベルがあります。
今回は他人のツイートを取得しなければならないので、デフォルトのEssentialではなくElevated プランを用いました。
(ElevatedプランはEssentialプランとは異なり申請が必要ですが、無料で使うことができます。)
リプライと元のツイートではいいね数に差があると考え、今回はリプライではないツイートのみを収集しました。
簡単なEDA
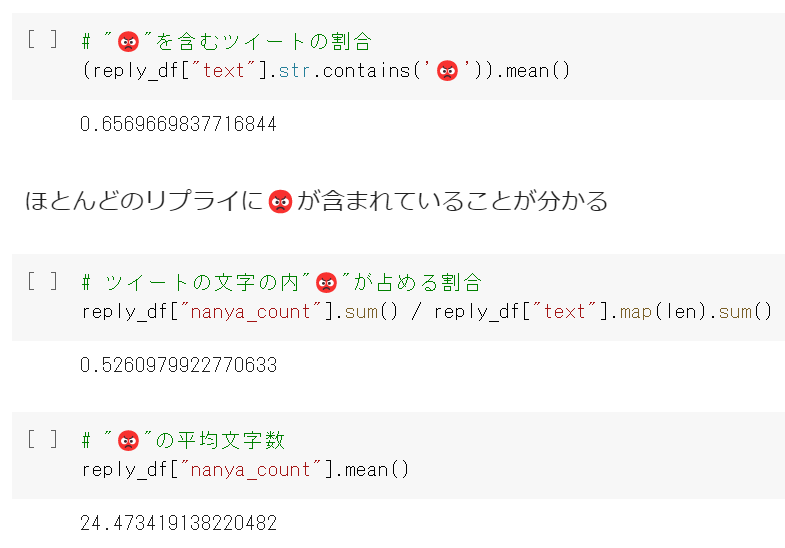
まずは😡を含むツイートの割合を調べてみましょう。

予想に反してかなり小さい値が返ってきました。意外に😡を含んでいるツイートは少ないようです。
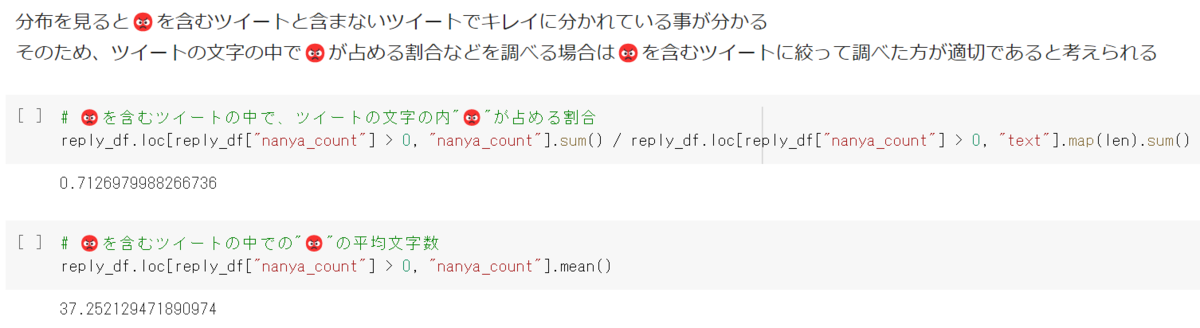
では次にいいね数と😡の関係性を可視化してみましょう
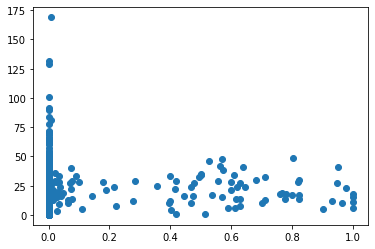
図は縦軸がいいね数、横軸がツイートの文字のうち😡が占める割合です。
…図を見る限りあまり関係性が無さそうにみえます。
次に、いいね順に並べたときの上位10件と下位10件のツイートの内容を見てみましょう


良いね数の下位10件はこれといって特徴がありませんが、上位10件にはABCの成績ツイートが多い事が分かります(10分の3がABCのコンテスト成績ツイート)。
競プロアカウントなのでこれは自然な結果と言えるでしょう。
BERTによっていいね数を予測し、判断根拠をLIMEによって可視化する
次に、LIMEを使ってどの部分がツイートの伸びに影響を与えているかについて分析したいと思います。
LIME(Local Interpretable Model-agnostic Explainations)とは、複雑なモデルを単純な線形回帰で近似することで解釈性の向上を目指す手法です。
BERTなどの複雑なモデルがどのようなところを判断基準にしているかを可視化して解釈する際に用いることができます。
今回はLIMEのLimeTextExplainerというものを使うのですが、これが回帰に対応していませんでした。
そのため今回は、いいね数を上位30%と下位30%の二つの集団に分け、2値分類タスクとしてBERTに解かせようと思います。
その後、学習済みBERTの判断根拠をLimeTextExplainerによって可視化して、ツイートのどの部分がツイートが伸びるか伸びないかに影響しているのかを調べてみました。
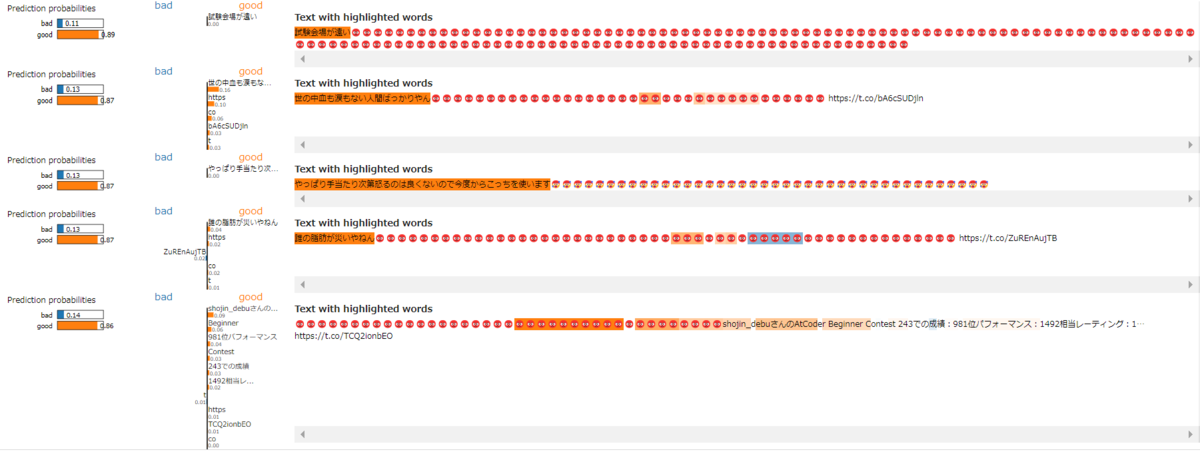

オレンジの線が引かれた部分がいいね数が多くなるとBERTが判断した要素、青色の線が引かれた部分がいいね数が少なくなるとBERTが判断した要素です。
図を見る限り😡がいいねの数に影響しているとは言えなさそうでした…
終わりです😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡😡